Overview
Experimental Results
Surmounting Terrain
Platform: 0.7m | Wall Angle: 60°
Platform: 0.7m | Wall Angle: 80°
Wall-assisted Gap
Gap: 1.2m | Wall Angle: 60° | Front view
Gap: 1.2m | Wall Angle: 60° | Side view
Gap: 1.1m | Wall Angle: 80°
Gap: 1.2m | Wall Angle: 80°
Stepping Stones
Discrete stones: length/width in 0.5–0.8 m | height variation in 0–0.4m
Discrete stones: length/width in 0.5–0.8 m | height variation in 0–0.4m
Simulation Environments
surmounting
stepping stones
wall-assisted gap
The blue and purple dashed lines represent the predicted current and next headings. The red and green grid lines represent the predicted distances from the robot's left and right feet to the desired current footholds, respectively. As these are scalar values, they are visualized using spherical grids.
Abstract
Parkour tasks for quadrupeds have emerged as a promising benchmark for agile locomotion. While human athletes can effectively perceive environmental characteristics to select appropriate footholds for obstacle traversal, endowing legged robots with similar perceptual reasoning remains a significant challenge. Existing methods often rely on hierarchical controllers that follow pre-computed footholds, thereby constraining the robot’s real-time adaptability and the exploratory potential of reinforcement learning. To overcome these challenges, we present PUMA, an end-to-end learning framework that integrates visual perception and foothold priors into a single-stage training process. This approach leverages terrain features to estimate egocentric polar foothold priors, composed of relative distance and heading, guiding the robot in active posture adaptation for parkour tasks. Extensive experiments conducted in simulation and real-world environments across various discrete complex terrains, demonstrate PUMA's exceptional agility and robustness in challenging scenarios.
Pipeline
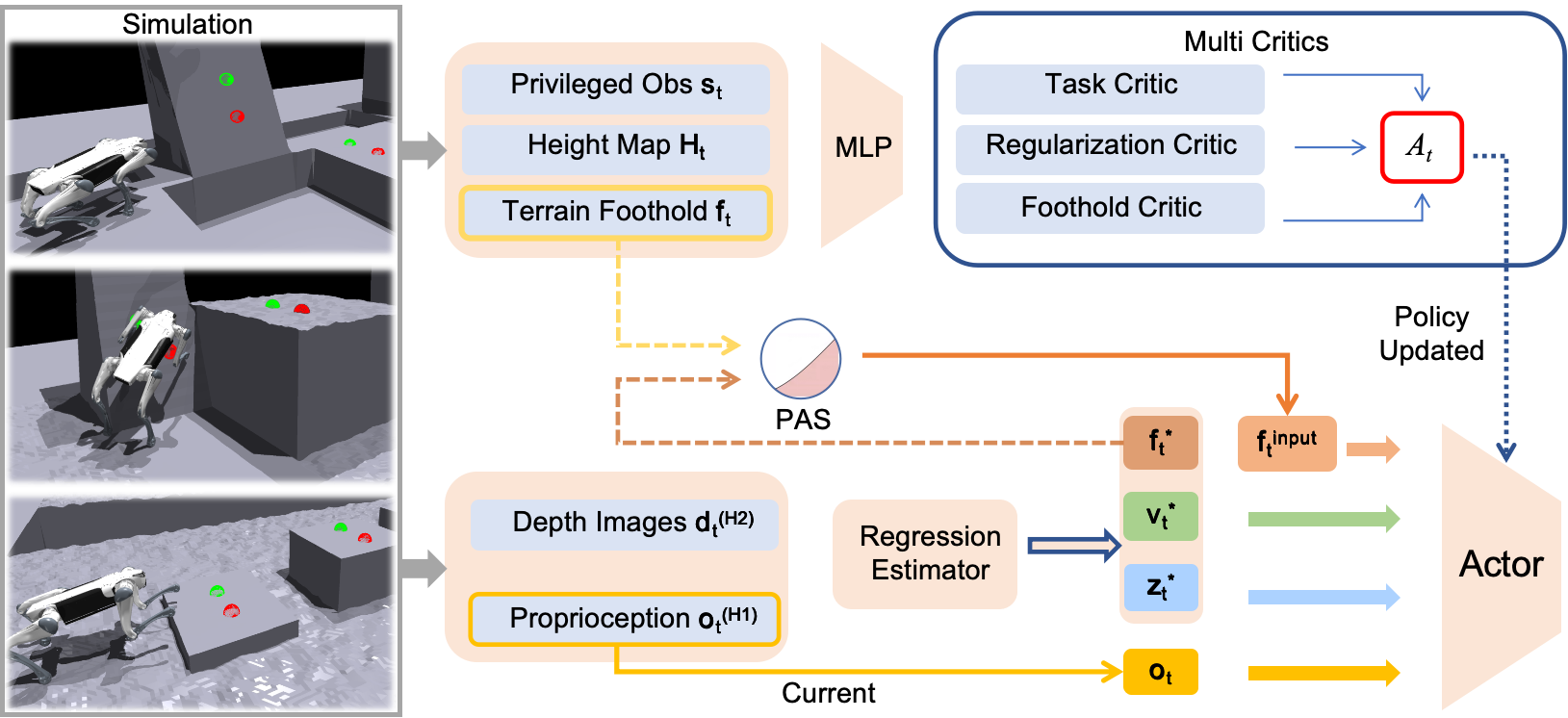
Overview of PUMA training framework. A velocity-tracking locomotion policy takes proprioception and depth images as input to predict egocentric foothold priors, base velocity, and latent terrain features. These representations are then concatenated with the current observations and fed into the policy network. Multiple critic networks are trained on distinct reward components to cooperatively optimize the policy. During training, a PAS strategy gradually replaces ground-truth footholds with predicted ones. The entire process is conducted in a single stage, with all networks optimized simultaneously.
BibTeX
@article{wang2026pumaperceptiondrivenunifiedfoothold,
title={PUMA: Perception-driven Unified Foothold Prior for Mobility Augmented Quadruped Parkour},
author={Liang Wang and Kanzhong Yao and Yang Liu and Weikai Qin and Jun Wu and Zhe Sun and Qiuguo Zhu},
year={2026},
eprint={2601.15995},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2601.15995},
}